 Autorem blogu je
Autorem blogu je 

Forth. Pro jedny samoúčelná hříčka, pro druhé geniální programovací jazyk, který neměl dostatečně účinný marketing. Těžko to dnes rozsoudíme, faktem ale je, že jazyk Forth stihl podobný osud jako jiný, svým způsobem revoluční jazyk APL. Oba přišly příliš brzy i příliš pozdě zároveň: příliš brzy na to, aby jejich kvality mohly být náležité oceněny, a příliš pozdě, než aby konservativní svět počítačových technologií dokázaly skutečně ovlivnit.
A oběma bylo jedno společné: zatvrzelý fanatismus jejich příznivců, kteří si nebyli ochotni připustit, že – v případě APL – programovací jazyk vyžadující zcela specifickou znakovou sadu prostě nikdo používat nebude, a, pokud jde o Forth, že text programu musí být srozumitelný, tak aby bylo na první přečtení aspoň zhruba jasné, o co v algorithmu jde.
Forth je bohužel typický write-only (případně write once, read never) programovací jazyk, kde význam algorithmu bez patřičné dokumentace přestává být jasný i autorovi již za několik hodin.
Nápadů má v sobě arci Forth hodně, a některé jsou opravdu chytré a užitečné, třeba ten, že proměnná je vlastně jen jiný druh procedury (zárodek budoucího objektově orientovaného programování!) nebo že přeložený program vůbec nemusí být sekvencí proveditelných instrukcí procesoru, ale může to být posloupnost odkazů na objekty (v terminologii Forthu nazývané slova), které se mají provést.
V 80. letech už sice Forth pomalu umíral (na IBM PC se nikdy ve větším měřítku neprosadil), ale přesto bych ho rád do svého emulátoru zařadil.
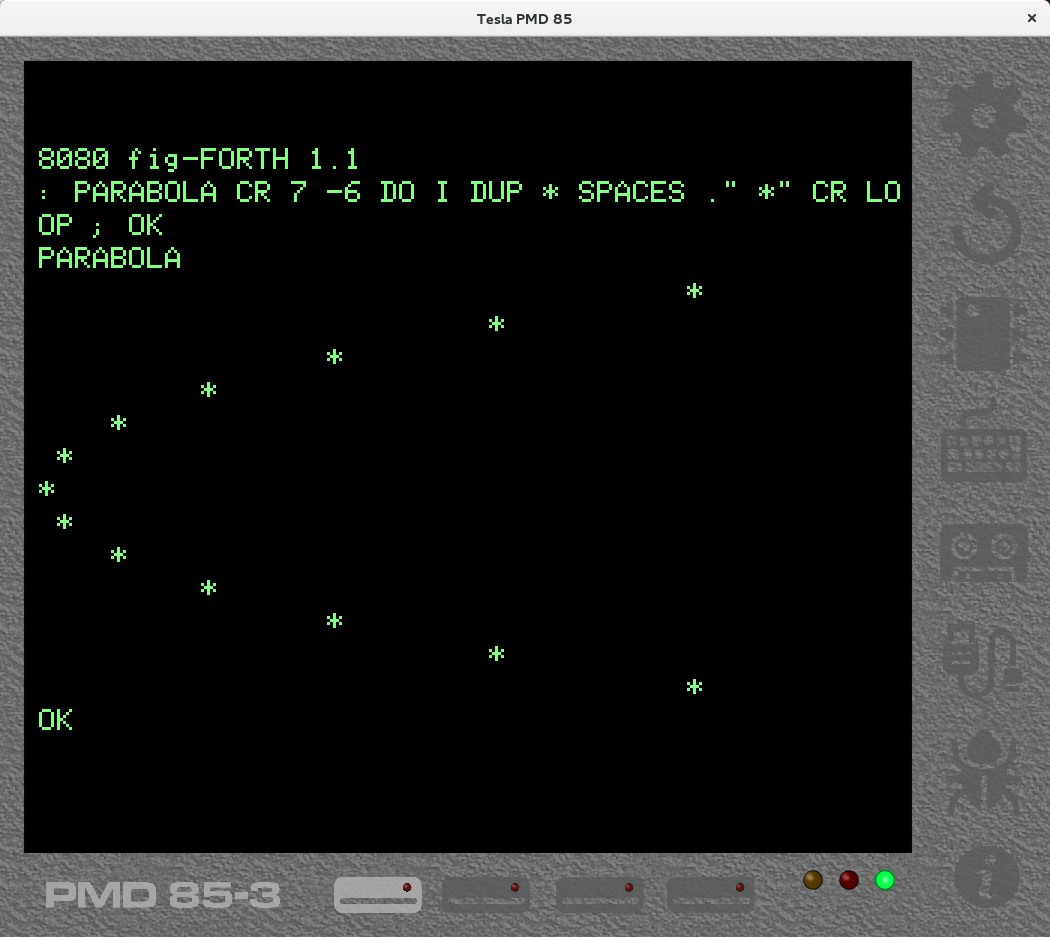
Původně jsem se domníval, že budu portovat fig-Forth (to se mi celkem podařilo, viz obrázek), což byl velmi slavný, arci dosti primitivní, Forth ze 70. let. Nelíbilo se mi ovšem, že s vytvořeným programem nelze rozumně pracovat, magnetofon se pro vývoj ve Forthu nehodí, a i když bych mohl vytvořit podobné pluginy, jaké mám pro BASIC a Pascal, výsledek by byl příliš závislý na použití mého emulátoru a nikde jinde by nebyl pro vývoj dobře použitelný.
Proto jsem další práci na Forthu odložil na dobu, kdy budu mít dokončenu podporu disketové mechaniky a bude tedy možné jak zdrojový kod, tak zkompilovaný produkt uložit na disketu. Také jsem sáhl po Forthu o generaci modernějším, F83, který mi pod CP/M fungoval bez jakýchkoli úprav, a mou prací bude vlastně jen vývoj knihoven, které umožní vytvářet software pro PMD 85 tím, že dodají podporu hardwaru: grafiky, klávesnice, magnetofonu atd.
Na CP/M intensivně pracuji, není to nic zvlášť náročného, můj vývoj momentálně stojí na tom, že bych chtěl mít přímo v emulátoru grafický manager disket, který umožní přenos souborů mezi nativním formátem emulátoru a všemi běžnými formáty, ve kterých se diskety pro CP/M vyskytují. Java je pro takový úkol velmi dobře přizpůsobena, jen je to prostě hodně programování.
Komentáře
pmd85.borik.net/_work/forth602.ptp
Ak sa nemýlim, tak implementácia Forth602 zodpovedá popisu, ktorý bol uvedený v seriály Rudolfa Pecinovského v ARA-7/84 až ARA-3/85.
pmd85.borik.net/_work/Forth_AR_84-85.pdf
Forth 602 je rozšíření fig-Forthu, bohužel se ale pro vývoj moc nehodí. Problém je v tom, že když pracujete s BASICem nebo Pascalem (se zapnutou kontrolou indexů), za normálních okolností se vám nestane, aby se systém zhroutil (ledaže voláte neodladěné subrutiny ve strojáku). Proto můžete celkem bezpečně program editovat a zapsat ho na kasetu až po nějaké době. U Forthu tohle nejde, stačí drobná chyba v programu a systém havaruje, s nepředvídatelnými následky pro obsah paměti. Tedy si nemyslím, že by jakýkoli Forth dal bez podstatné dávky masochismu provozovat bez disketové jednotky.
Forth v komunistickém vydání byl opravdu write-only velice často. Ostatně jako třeba dnešní Perl, apod. Dnešní Forth už je dost jiný.
Forth je jazyk pro malé věci a tam, kde je třeba efektivita. Proto Forth vcelku běžně řídí části různých kosmických raket a družic nebo různé vestavěné systémy. I poslední rakety nesou mnoho procesorů programovaných ve Forthu. On ten jazyk má mnoho výhod, které člověk ocení, ovšem nikoli při programování vzhledu faktury na Personal Computer.
APL podle mého spíše zapadá pro styl „všechno předěláme/vytvoříme podle sebe“, který už dře. Je to totéž, co způsobuje mou čím dál větší nelibost třeba nad TeXem.
Miloslav Ponkrác
U C např. máte zaručené jen minimální rozsahy, ale můžete si snadno přetypovat, cokoli potřebujete, a pracovat s vlastními typy. U Forthu jste v situaci, že u osmibitů bylo slovo šestnáctibitové, u šestnáctibitů dvaatřicetibitové a dnes, např. u gforthu, je 64bitové. Software se tak stává dokonale nepřenosným, nemluvě o tom, že každý Forth přinesl specifická slova, např. pro práci se slovníky/kontexty. Výsledek je jedním slovem nepoužitelný: v C se používá dodnes 40 let starý kod, ve Forthu (podobně jako v Javě) byl 10 let starý kod k ničemu a musí se upravovat; paradoxně pomohla až "smrt" Forthu, který se díky tomu jakž-takž ustálil.
Příliš mnoho enthusiasmu škodí.
Mimochodem, tento dokument popisující standard Forthu znáte? lars.nocrew.org/dpans/dpans.htm
Vezmu-li programovací jazyk C, tak velmi dlouho jel bez faktického standardu, asi tak 20 let. Moc toho neuměl, a až ANSI C ho trochu zkultivovalo.
C++ bylo na tom stejně, standard dostalo až po historicky dlouhé době v roce 1998. Také zhruba 20 let, než dostalo standard. Dobře si na to vzpomínám, jak se C++ v dobách před standardem neustále měnilo pod rukama a nic nebylo jisté.
A stejné to bylo s Forthem.
Přenositelnost v C je také kouzelná. Umí pracovat třeba fseek se soubory delšími než 4GB? Kdo ví? Záleží na implementaci. Čistě teoreticky, a to platí stále, není zaručeno, že bajt = 8 bitů. Výraz (65535 + 1) může dávat na různých kompilátorech C různé výsledky. V zásadě je na tom C stejně jako Forth zastara, celočíselný literál bez suffixu může být cokoli.
Těch skutečně přenositelných jazyků je naprosté minimum, C ani Java mezi ně opravdu nepatří. Ačkoli lze zdrojové kódy napsat dostatečně přenositelně, a i já sám mám desetiletí staré C kódy, které jsem bez změny přeložit – což jsem si také zkusil.
Miloslav Ponkrác
Porovnáte neporovnatelné. Jednak tady byl faktický standard K&R C, jednak lze v header filu nastavit typy a další vlastnosti jazyka tak, aby C fungovalo podle představ programátora. U Forthu to možné není, a nepomohlo by, ani kdybyste preprocesorem přepsal např. všechny DUP na 2DUP nebo naopak. Délka buňky je základním implementačním parametrem, a máme-li dnes tři různé délky, máme i tři různé fatálně inkompatibilní Forthy.
Nebo vezměte Forth 83, který změnil proti fig-Forthu i tak základní věci, jako je fungování LEAVE nebo representaci booleovských hodnot. Přímá cesta do pekel.
1) Jste si jist, že různé C kompilátory pro 8bity a mikrokontrollery včetně různých exostických plně vyhovují standardům? Že zdroják napsaný pro toto byste přeložil jinde? Myslím, že bychom se občas velice nasmáli.
2) K & R nebyl standardem. K & R je terminus technicus pro jazyk, kterých byl popsán v knize „The C programming language“, kterýžto popis měl do standardu daleko a velmi mnoho věcí bylo třeba si domyslet.
3) Forth je jiné paradigma, přímé srovnání s C je nesmysl.
4) Délka buňky je stejný platformově závislý bazmek, jako je v případě C délka int. Stejně jako naprosto netušíte, jakou délku bude mít int, tak je tomu u Forthu.
Protože se v médiích píše obvykle o platformách s int o délce 32 bitů, tak to navenek budí nesprávný dojem, že je C bůhvíjak jednotné. A také bůhvíjak optimální. Jakmile začnete C strkat z tohoto středu na odlišnější platformy, začne dostávat na zadek jak přenositelnost, tak kvalita a optimalita kódu lezoucí z C.
5) Jazyky C, Forth ani Java – zde nějak zmíněné, nejsou ani jeden z nich přenostelnými programovacími jazyky.
Miloslav Ponkrác
Ve Forthu se nic podobného naprogramovat nedá, programátor je zcela v zajetí toho, jak široké má typy.
C není jednotné, to ani nikdo netvrdí, ale jeho nejednotnost lze obejít. Nejednotnost Forthu je neřešitelná.
K&R nemá formu standardu, ale programovat se v něm docela dobře dá, a většina moderních kompilátorů si i s takto zastaralým kodem poradí.
1) Protestuji proti tomu bez ztráty rychlosti. Různě široké int typy samozřejmě mají různou rychlost. Takže bez ztráty rychlosti to nebude. Na x86 je třeba obvykle nejpomalejší 2 bity šířka integeru, což je obvykle short int. Ostatně norma jazyka C říká, že „int“ by měla být taková šířka celočíselného typu, která je na dané platformě nejrychlejší. Tedy rychlost je ovlivňována zvolenou šířkou, a to velmi výrazně.
2) Programátor je v zajetí šířky typů. Je to tak jak v C, existuje základní typ, který se v C jmenuje int, a může být různě veliký.
3) Ani C ani Forth nemá nekonečnou šířky integerového typu, tedy existují tu omezení v obou jazycích. Můžete vložit mezivrstvu, ale jen potud, pokud kompilátor vámi chtěnou šířku int podporuje.
4) Forth je zaměřený na efektivitu, spolehlivost a je blíže stroji. A má jiné paradigma. C je nástroj pro psaní kernelu operačního systému.
I když odhlédnu od Forthu, je to právě extrémně špatná a nedomyšlená práce s int typy, která byla poslední kapkou, proč jsem po 20 letech psaní v C/C++ k těmto jazykům získal trochu odpor. Hloupěji už to fakt vymyslet nešlo.
Mám sadu char/short/int/long/long long, což je sice na pohled fenomenální, ale jinak k ničemu. Není nijak určeno, jak široké typy to budou, pokaždé je to jinak.
Celá standardní knihovna C/C++ používá tyhle neurčité typy, úplně si představuji, jak se ďábel satan někde pokaždé chechtá, když někdo používá standarndí knihovnu. A ptá se: bude funkce strtol() schopná pojmout jaký rozsah čísel? Jak přenositelně napsat formátování 4 bajtového int čísla uvnitř funkce printf()? Zvládne funkce „long ftell(FILE *)“ práci se soubory nad 4 GB? A tisíce dalších otázek.
A jak mám svou mezivrstvu pomocí integer a #define namapovat tak, aby všechny výše uvedené a mnohé další problémy se standardní knihovnou řešila přenositelně? C totiž nemá dostatečné prostředky v jazyce k tomu, aby přenositelně všechny šířky int vyřešil.
Jediná možnost, jak vyřešit v C všechny neurčitosti v int typech a jejich šířkách a oborech hodnot je zahodit C. Případně napsat generátor, který bude generovat na výstupu standardní C. Prostředky jazyka C to totiž nejde.
Miloslav Ponkrác
Forth nezemřel, a nezemře. Jen nejspíše nikdy nebude mainstream. Stejně jako to je třeba s Adou nebo Fortranem, LISPem, nebo dalším.
Forth v provedení pro 8bity bych vzdal úplně stejně, jako bych nechtěl programovat třeba v Borland C++ 1.0, nebo kompilátoru jazyka C pro Atari – protože obé (vlastně tré, řekne se tak trojice? nevím) je beznadějně zastaralé, málo použitelné a zcela neodpovídají ani dnešním standardům těchto jazyků.
Jednoduše je mainstream, a Forth do něho nepatří. Je to asi to samé, jako kdybychom řekli, že ve fyzice Hamiltonova formulace dynamiky umřela, protože je tu Newtonova mechanika. Nebo že kvarterniony nemají význam, protože tu máme vektorové prostory a vektory. Pro většinu lidí nemá Forth význam.
Ale zcela určitě byste nic kriticky důležitého neprogramovali ani v C, ani v žádnéím mainstreamovém programovacím jazyku.
Vy chcete po Forthu, aby byl jako C, a kdyby to udělal, tak by Forth skutečně zemřel. Neměl by smysl. Nejlepší Céčko je a bude vždycky C.
Mainstreamové jazyky mají tu nevýhodu, že jsou špatně algoritmicky/strojově prověřitelné, a z toho vyplývá i špatně optimalizovatelné. Dodnes nechápu, proč jsou tak jazyky konstruovány pro hlavní proud, ale prostě jsou. To znamená, že s rostoucí velikostí programu exponenciálně rostou náklady na zajištění bezchybovosti. Jinak řečeno, tam kde chyba udělá velkou škodu, je nikdo nenasadí.
C bylo děláno na malé projekty. Původní unix kernel v C měl pár desítek tisíc řádků. Jednotlivé programy typu list, sh, grep, rm, atd. byli také maličké programy. Pro tyhle věci bylo C navrženo. Pak se to zvrtlo, a někteří se v C snaží dělat obrovské projekty, jako linux kernel nebo gcc, což považuji za typické sado maso. Jde to, ale neefektivita vývoje a počet člověkoroků by položil každou komerční firmu, kdyby zkusila totéž. Někteří nakonec pod tlakem zoufalství v C utekli alespoň k C++ (gcc, Windows).
Ostatně ani vy sám nepíšete své emulátory v C, pokud je mi známo.
Miloslav Ponkrác
Funguje mi na 8080 Small-C (které je ale chudé a neoptimalisované) a zakrátko mi bude fungovat SDCC. Forth nikoli, ten je s moderními nástroji fatálně nekompatibilní.
Nebo že kvarterniony nemají význam, protože tu máme vektorové prostory a vektory.
Spíš tensory, ale to je technický detail.
Portovat na 8080 ANS Forth (gforth) by zřejmě nešlo už z důvodu potřebné velikosti kodu, a obávám se, že by to stejně můj problém, tj. jak vygenerovat cílový kod, který neobsahuje nepotřebná slova, nevyřešilo.
U Forthu mám intensivní pocit toho, co se říká (neprávem) o učení se Linuxu: že je to jako learning to drink from a garden hose.
S Forthem je to stejné jako s Linuxem, buďto budete tlouct hlavou o stěnu, že to chcete jinak – a pak je lépe se nepřemáhat. A nebo je třeba pochopit, že všechno má svou filozofii.
Já jsem hodně věcí přehodnotil, když jsem se párkrát dostal do krizové situace. Tedy kdy šlo o výsledek a každému bylo šumafuk z týmu, v čem to bylo programováno. Pár opravdu stresových situací, a začal jsem prudce oceňovat a rozdělovat na pomocníky a ty druhé. A hodně jsem umenšil osobní preference a emoce k různým operačním systémům, programovacím jazykům, technikám, apod.
V zásadě existovaly pouze 3–4 převratné objevy/revoluce ve vyšších programovacích jazycích, ze kterých současné IT žije: 1) vznik Fortranu, 2) vznik Algolu, 3) vznik Lispu, 4) vznik Forthu. Myslím tím 4 objevy, které by byly přelomové, praktické a někam svět posunuly. (Tím trochu reaguji na nějakou z našich dřívějších debat, kde jste zavrhl jakýkoli přelom a doložil ho třeba vznikem C nebo unixu či čímsi – což přelomy paradigmat opravdu nebyly.)
Záměrně jsem napsal předchozí odstavec, protože Forth je jiné paradigma – proto je nepochopen, pokud jej srovnáte s čímkoli z hlavního proudu. To je největší překážka. Ale pokud mu věštíte smrt, tak dříve umře C než Forth, pokud by se dostalo do krize. I když Forth bude stále někde vzadu, o kteérm se nebude mluvit.
Když vezmete libovolný dnes programovací jazyk, tak má geny z některé této čtveřice. Forth prostě existovat bude – a také má spousty levobočků a kukaččích dětí, které nadělal.
Třeba takový Postscript a následně PDF je v zásadě jen prekabátěný Forth.
Miloslav Ponkrác
Forth neoceníte na standardním hw, desktopu – pokud nejste nadšenec. Ale jakmile je embedded, a potřebujete řídit nějaký hw neklasického typu, tak je Forth geniální.
1) Forth je nejpružnější programovací jazyk co existuje.
– C/Java/... považuje program a data za 2 různé věci a data nemohou měnit obecně program (bez znalosti strojové podoby platformy pod ním).
– Funckcionalní jazyky ála LISP mají data a program totéž: je to reprezentace seznamů, ale neumožňují měnit interpretr nebo editor ve kterém píšete.
– Ve Forthu můžete měnit všechno. Je to ještě vyšší zobecnění, než u LISPu či jiných funkcionálních jazyků, a velmi kompaktní celek. Forth je napsán sám v sobě, a nejsou v něm oddělené fáze vývoje.
2) Forth nepotřebuje pod sebou žádný operační systém. (A jak se to hodí, pokud nemáte standardní hw. Nedávno řada procesorů s programy ve Forthu doletěla na kometu a vědecky jí zkoumala.) Zároveň může bez problémů nad libovolným operačním systémem pracovat. (Na rozdíl od třeba Smalltalku, který lépe pracuje bez operačního systému a s ním to docela dře.)
3) Forth s veškerým kompilátorem/interpreterem + vývojovým prostředím + debuggerem vyvinete za 14 dní od nuly na jakoukoli platformu (klidně bez operačního systému na syrový hw zdůrazňuji). Dokonce je znám případ, kdy celý Forth na novou platformu implementovalo 11leté dítě. Je to jednoduchoučké a nenáročné.
4) Forth na rozdíl od třeba C a většiny mainstreamu nemá sebemenší problém s masivním multitaskingem či exotickými architekturami. Je prostě flexibilní a funguje tam, kde se C těžko vydáte a nebo velmi těžce pohoříte, případně to bude značně masochistické či nepřesvědčivé.
5) Zdrojové programy ve Forthu jsou mnohem mnohem kratší, než programy třeba v C/C++ nebo mainstreamových jazycích – pro stejný výsledek.
– Většinou to funguje tak, že projekty v klasických mainstreamových jazycích se obvykle přetahují časově a trvají déle proti plánu. U Forthu je to často opačně, hotovo je rychleji, než se plánovalo, zvláště pokud to plánuje někdy podle předchozích zkušeností z mainstreamových akcí.
Miloslav Ponkrác
Forth mě zaujal jako koncepce (Postscript roky používám, takže postfixová notace pro mě není nic nového), ale nedává mi pro programování osmibitových procesorů oproti assembleru nic navíc, naopak vše komplikuje.
Forth není postfixová notace, klidně by se dalo ve Forthu v klidu napsat vyhodnocování běžných výrazů v běžném tvaru jako v C. Nebyl by to nejmenší problém. O tomhle Forth není.
Forth je mimo jiné o svobodě tvořit hw na míru. Když chcete používat C, potřebuje přesně daný mainstreamový background + operační systém + určité úzce vymezené koleje. To samé by se dalo říci o unixu. Jak unix, tak C má sktriktně dáno, na jakém hw běží a je to úzké rozpětí. Kolik jste viděl unixů na 8bitových počítačích? C na 8bitové počítače jsou, ale jsou ohnuté a kompromisní.
Vy si můžete navrhnout hw a jeho architekturu přesně na míru potřebám, a do několika týdnů ve Forthu od nuly udělat vekšeré sw vybavení včetně multitaskingu. Přesně proto je Forth v Postcriptu, protože ta tiskárna mohla mít uvnitř cokoli za procesor i architekturu, klidně i velmi slabý procesor – a vy jste nemuseli dumat, jestli uvnitř firmware tiskárny bude linux, windows, nebo wxworks, atd. – a prostě během něklika týdnů celý firmware od nuly máte. Tisíckrát rychleji než v asm. A to je Forth. Proto je Postscript prekabátěný Forth, a proto to bylo zvoleno, protože takto se dá jeho implementace rychle zařídit v jakékoli tiskárně či krabičce.
O tom to je. Máte-li standardní hw, jehož výkon by klidně uřídil sám hejno raket až na Sírius, a k tomu 30 let vyvíjené mocné vývojové prostředí a jazyky – pak je Forth krokem zpět. A mezi námi, leckterý 8bit byl výkonnější, než to co řídí palubní počítače v raketách dodnes.
Znovu připomínám bezpečnost, paralelnost a prověřitelnost Forthu. S dvěma zásobníky o 16 nebo 32 položkách kapacity to prostě funguje.
Až budete dělat kritický a špičkový real time operační systém, nebo potřebovat rychlost reakce, pak opět: Forth reaguje na přerušení okamžitě, vše je na zásobnících, nic není třeba ukládat a obnovovat za stav. Klasické paradigma ukládá při přerušení stav na zásobník, nebo alespoň přepíná sadu registrů a zakazuje další přerušení, a vytváří nový stav pro přerušení, a teprve pak něco dělá.
I na tu nejšílenější hw architekturu, kterou si vymyslíte, můžete implementovat Forth. A implementujete to ho strašně rychle. Zatímco unix či C si strašně vymýšlí, co pod sebou chce mít, a co všechno potřebuje, aby se uráčilo vůbec fungovat. U mainstreamu to není problém. Ale pak v případě C či unixu tyto diktují, jak má vypadat hw. Ve Forthu je to driven by hw a máte svobodu sletovat přesně to co potřebujete.
Mimochodem, sám autor Forthu navrhl procesor (sám v CADu), a ten se realizoval. Měl 5 bitů pro instrukce, tedy místo pro 32 strojových instrukcí – a ani je všechny nevyužil. A podobné procesory létají do kosmu. Kosmos není přátelské prostředí, je tam radioktivita a každá složitost navíc přináší další chyby a další nutné kontroly a opatření v sw, jak ty chyby ošetřit. Každý další tranzistor, nebo každý další bit paměti RAM může mít stav narušený kosmickým zářením. A musí se s tím počítat a sw to musí umět ustát. Troufnete si na to s C? Já ne. A ani NASA ne.
Miloslav Ponkrác
Resumé je, že kdybych chtěl pro PMD napsat něco ve Forthu, musel bych si napsat jeho cross-compiler sám, prakticky "od nuly", a Forthem bych se mohl nejvýš inspirovat. Táži se, zda to má vůbec smysl, a nejsem si jist. Možná by měl to bavilo, kdo ví.
Pokud uděláte kompilátor, pak se vše vykoná na úrovni strojových operací a pointerů. Naprostá většina maker bude u kompilátoru inlajnována, protože to dává z hlediska optimalizace většinou vyšší smysl. A jen část bude volána podobně jako podprogramy.
Tak to je ale u všech programovacích jazyků – interpretr musí v paměti držet slovník identifikátorů, kompilátor (je-li dobře navržený jazyk) ne. U některých dynamických jazyků by bylo nutné i v kompilátoru slovníkovat (např. Python).
-------------
Forth je při kompilaci velmi mohutně optimalizovatelný. Vyleze z toho velice malý, čistý a rychlý kód. Malá makra se překládají do jedné či několika strojových instrukcí, takže je lépe přímo inlajnovat. Volání podprogramu znamená jedinou instrukci call, protože není třeba vytvářet žádný stack frame, ani předávat parametry, ani si přebírat návratové hodnoty. Různé zapsané sekvence příkazů lze snadno zkracovat, protože matematicky je to dobře přehledné a uchopitelné i pro optimalizátor.
---------------
Pro mě osobně nedává vůbec smysl zabývat se jakkoli PMD z praktického hlediska, smysl to má pouze z hlediska nadšeneckého. Při otázce, zda má smysl zabývat se na PMD Forthem či jakýmkoli jiným jazykem, je odpověď pro mou osobu jasná.
Ale jinak bych to viděl tak, jak píšete: Používat historický Forth je asi k ničemu.
Krása Forthu je v tom, že můžete rychle stvořit poměrně efektivní vývojové prostředí tam, kde máte plnou volnost při vytváření svého hw, a nepotřebujete operační systém. Další věc je, že Forth je efektivní (z hlediska optimality a rychlosti běhu) i tam, kde není efektivní C.
Pokud nejste nadšenec do Forthu, asi bych se na něho tam, kde je k dispozici C nepouštěl.
Ostatně v zásadě všechny virtuální stroje, co jsem měl tu čest zkoumat, jsou v podstatě Forthovské filozofie. Když se podívám na JVM (Java Virtual Machine), nebo na mašinu .NET frameworku – to je v zásadě vykonávač instrukcí, které jakoby Forthu z oka vypadly s mírnými modifikacemi. On je Forth velice efektivní, rychlý a optimalizovatelný – a tak umožňuje i přes tuto abstrakci rozumně rychle jet i obludám jako je Java nebo C#.
Miloslav Ponkrác
Jak jsem vícekrát napsal, do emulace PMD 85 jsem se pustil pouze proto, že jsem se chtěl naučit Javu, ale když už se mi to (relativně úspěšně) podařilo, nelituji toho, protože mám na hraní počítač, který znám do nejmenšího detailu, "do posledního šroubku", tak, jako nebudu nikdy znát třeba své PC.
Já chtěl jen sdělit, že když nemáte silně mainstreamovou a standardní architekturu, tak existují nástroje, které si s tím poradí. V minulosti to bylo i v mainstreamu časté, protože v počítačích byl každý pes jiná ves, a standardizace naprosto žádná. A Forth tam exceloval. I proto, celkem chytře, socialistický blok, prosadil jako základní standard jazyků Forth.
Což se drží dodnes. Nad Forthově orientovanou architekturu se napíše kompilátor do více méně Forthu v binární podobě – a nazve se to třeba Java nebo C# nebo Postcript, atp. A většinou se pak troubí do světa, jak je to prudce přenositelné, což je základní věc, proč Forth byl stvořen.
---
Výrobci často vynikajících architektur, bohužel odlišných od mainstreamu, mají často bolení hlavy z jazyků jako C, apod. Protože jsou to v zásadě jazyky totálně neflexibilní a vyžadující přesně své.
Takže takový Cray, který vyrábí superpočítače, to musel nějak řešit. Historicky to řešili třeba LISPem, což je daleko flexibilnější jazyk, než C. Teoreticky lze C opentlit MPI a OpenMP a nějak to napsat v něm – ale to už je sado maso. Pro grafiky vznikla jakási CUDA. To všechno proto, že IT chce použít Céčkoidní styl tam, kde C nemůže. Crayů došla trpělivost a vymysleli jednoduchý, ale plně paralelní jazyk Chapel. To je zase opačná strana směrem od Forthu.
---
Ostatně C není kdovíjaké kvality. Když se podívám, tak na x86 architektuře trvalo kompilátorům několik desetiletí, než dosáhly dnešního stupně optimalizace výstupního kódu. A stále je co zlepšovat. Je vlastně docela humorné, že Intel C kompilátor je schopen ze stejného zdrojového kódu udělat třeba 2 × rychlejší program, než udělá gcc či Microsoft. Už to ukazuje, že C moc optimální není pro rychlý a efektivní kód, a iluze rychlosti C se dosahuje tisíci člověkoroky věnovanými vývoji kompilátorů – a stále nejsme u vrcholu.
Představa, že optimalizované C bude k dispozici na okrajové plarfotmy je … nechám to na vaší úvaze.
Existují zkrátka jazyky a prostředky, jak na odlišné architektuře dosáhnout efektivního kódu jinak, než že si na 30 let sednete a budete vyvíjet optimalizovaný C kompilátor srovnatelný v optimalizaci s x86 či většinovými architekturami. Jedním z nich je assembler, dalším – efektivnějším – je Forth. A ještě stovky dalších možností.
---
Miloslav Ponkrác
Dnes se Forth pouziva treba tam kde vyzaduji portabilitu. Aby to same bezelo na PC, na mobilu, v browseru a certvi kde jeste. Pokud je problem dostatecne maly (na velke projekty Forth neni), nevyzaduje i ten posledni zdibec vykonu a (hlavne) najdou nekoho schopneho kdo se Forthu neboji. Ten clovek si pak udela vlastni miniaturni verzi Forthu, vlastni vyvojove prostredi a je s tim nadmiru spokojeny - ma presne to co chtel, nic vic, nic min.
Udělat kompilátor pro Forth nic těžkého není, protože Forth je v podstatě druh assembleru. Jediná práce je nahradit jména adresami v paměti a nebo přímým vložením do kódu, to je celé v kroku od interpreteru ke kompilátoru.
Pokud by měl navíc kompilátor optimalizovat nad rámec nahrazení jmen, pak už by to byl opravdu velký a těžký projekt – nicméně i bez toho je kompilátor sakra rychlejší než interpretr.
Problém Forthu je právě špatná práce s řetězci i s identifikátory programu. Vše je globální, nejsou tu prostory jmen ani lokální jména – a to je jediné co zabraňuje větším projektům, vůbec nic jiného.
Kdybych dnes psal kompilátor/interpretr Forthu, tak by jména byla Unicode. Každý modul by měl lokální tabulku jmen a celé prostředí globální. Všechna jména by se hledala pouze v lokální tabulce, pokud by měla speciální prefix pro globální jména, tak pouze v globální. Čímž by to nebyl standardní Forth, ale použitelnější.
Ve své podstatě je Forth a jakoukoli odvozeninu si uděláte něco, co umožňuje rozlet, křídla a funkčnost na jakémkoli hw.
Miloslav Ponkrác
forth.com/.../swiftforth-optimizing-compiler.html
Já tam těžké optimalizační strategie nevidím.
Soudě podle jejich ukázky, jejich rozhodnutí vychází z toho, že ebx = vrchol zásobníku, [ebp + 4 * (n-1)] obsahuje další položky datového zásobníku. Zásobník návratových adres je pak klasicky na [esp].
Asi chápu, proč se tak rozhodli, protože obecné calling convention pro x32 je, že registry ebx a ebp se zahovávají při volání podprogramů, mohou tedy volat C podprogramy nebo Windows či Linux API funkce.
Nicméně pořád tam nevidím optimalizace, ke kterým by se nedošlo prostým inlajnováním makra > a následným vyházením duplicit na zásobníku.
Optimalizovat ify musíte tak jako tak, protože se tak trochu vymykají z prostého lineárního kódu a je třeba se nalézt sekvence podvýrazů podmíněných příkazů. To musíte v zásadě udělat i u interpretru.
Naopak jim úplně základní optimalizace ve Swiftu chybějí! I ty co by udělal nejhloupější kompilátor. Proč všude používají nejdelší a nejpomalejší instrukce podmíněných skoků? x86 má nejkratší instrukci JLE rel 8, pak delší JLE rel16 a nejdelší JLE rel32. A všude, i ve výsledném optimálním kódu vidím tu nejdelší variantu, ačkoli by všude stačila ta nejkratší. Máte tedy namísto 2 bajty dlouhých instrukcí podmíněných skoků všude ve výsledky 6 bajtů dlouhé instrukce.
Nezlobte se na mě, ale Swift na optimalizace zcela a zvysoka kašle. Nedělá ani naproatý základ, který naprogramujete za pár minut.
Schválně jsem si napsal výslednou rutinu, kterou bych z toho Forthu dostal i relativně ne příliš silnou optimalizací (ne jen inlajnem), protože rutinně mohu nahrazovat if s porovnáním. Výsledný kód je po všech stránkách lepší, je kratší (13 bajtů oproti 16 ze Swiftu), je rychlejší, a nemá skok, což je další rychlostní plus na procesorech:
83FB09 cmp ebx, 9
8D4307 lea eax, [ebx + 07h]
0F4FD8 cmovg ebx, eax
83C330 add ebx, 30h
C3 retn
Zkrátka Swift je více marketink a trochu práce, než „brutálně“ optimalizující kompilátor. Když si nedá práci ani s tím, aby používal v instrukcích short podmíněné skoky, tak tento titul mu nepatří ani náhodou.
Miloslav Ponkrác
RSS kanál komentářů k tomuto článku